

Central England Temperature
It has frequently been stated that 2oth century warming was “unprecedented” or “cannot be explained”. This article sets out to test this assertion on CET the longest available temperature series. I find the CET data rejects the hypothesis of ‘climate change’ (>58%) & current ‘global warming’ (>72%) and that overall global temperature has not changed significantly more than would be expected. I do however detect a marginally higher trend over a 50year period ending 2009 with about 2.5σ and a 35% chance of occurring normally within the dataset. However this is inconsistent with an established trend as progressively shorter periods toward the present time tend toward lower trends (40yr: 1.7σ, 30yr: 1.3σ, 20yr: 1.6σ, 10yr: -0.9σ).
I am therefore more than 58% certain that the data is consistent with natural variation and more than 73% certain that any current warming is within the normal range expected.
Introduction
Many such as the IPCC have repeatedly asserted that we are seeing abnormal changes in the temperature particularly after the latter half of the 20th century (i.e. post the global cooling scare of the 1970s). In order to assess these statements I wanted to know the typical trends that we see in the climate record and to use these to make my own assessment of whether my assertion that “the temperature record is consistent with natural variation” can be supported from the data.
The reason I have not done this before, is that it is simply false to base any statistic on a simple standard deviation such as employed by Hansen who completely falsely came up with a figure that climate change was more than 99% likely to be caused by humans. To show how ridiculous this figure is, his statistic would also mean that the little ice, age, medieval warming and all the ice-ages are “human caused”.
The problem is that Hansen falsely used statistics that only work when the temperature of each year is totally unrelated to the previous years. And therefore any change common to a group of years would represent external forcing. However this is not how the real climate behaves. We have years, decades, centuries, even millennium with higher or lower temperatures. Therefore, in order to know what is “abnormal” or in the common language of climate alarmists what is “unprecedented” we must first know what is normal.
Only when we know what is normal can we have nay hope at all of spotting a departure from normality. So, when we only have global temperature data from around 1850 and only one full century to compare with itself, anyone who says “the twentieth century rise is abnormal” is either ignorant or being dishonest.
It is that simple.

Variability of observed global mean temperature as a function of time-scale (°C2 yr–1)
from figure 9.7 IPCC (2007)
The problem as the IPCC know full well from their figure 9.7 of the 2007 report (shown right) is that the natural variation shown in global temperature varies dramatically depending on the period over when measurements are taken.
So, whilst it would be possible to make a valid statement about warming within any decade in the global temperature record, because we have a a sample of 16 decades to compare it with, it is nonsense to make any statement about century scale warming being “abnormal” when we only have one full century of data which must both serve to work out what is “normal”.
To illustrate how we must know “normality” let me take the extreme example of a 3C temperature change. Is this within the range of “normal variation”. The answer is that it all depends. Below is the estimated temperature change over an ice-age cycle.
 Here we can see that the suggested change of about 0.75C over the 20th century is completely insignificant compared to the 8C change that the globe experiences going through the ice-age cycle. So, a 3C change over 100,000 years would be entirely within the normal changes seen in the climate, but a 3C change seen in one decade would be extremely unusual in the available global instrumentation climate record.
Here we can see that the suggested change of about 0.75C over the 20th century is completely insignificant compared to the 8C change that the globe experiences going through the ice-age cycle. So, a 3C change over 100,000 years would be entirely within the normal changes seen in the climate, but a 3C change seen in one decade would be extremely unusual in the available global instrumentation climate record.
Aim of analysis
There is simply insufficient global temperature data available to test the hypothesis that 20th century warming is “abnormal”. However, temperature data is available regionally for longer periods which could test whether there has been any sign of unprecedented warming regionally. The longest of these is the Central England Temperature series which is available from about 1660.
I therefore decided to work out the typical trends over various periods and then used this to assess whether there were any “abnormal” trends in the record.
What makes my approach different is that I am not making any assumptions about how the climate behaves except that what is “normal” in any period should be “normal” within any similar length period. The key to this approach is that I am treating each time period as a different dataset. Therefore the appropriate test is to determine the variation typical in that time length and then to assess whether any period has a trend that is significantly outside the normal variation expected for that length of period.
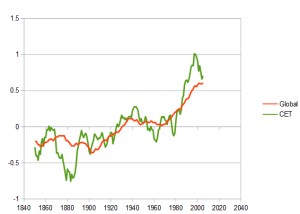 Does CET correlate with Global temperature
Does CET correlate with Global temperature

First however, I need to show that CET is a reasonal proxy for global temperature. To do this I will check how well CET is correlated global temperatures. A comparison of the two is shown right (offset to have zero average and with 11year moving average). Whilst the two have significant differences, the important trend referred to as “global warming” is present as well as the main 1970s “global cooling” dip which gave rise to the global cooling scare.
A calculation of correlation for the available data shows:
correlation coefficient R = 0.54
This indicates that moderate correlation is present. (And I will add this is much better than any tree-ring proxies).
Method of Analysis
- Data was the yearly average taken from Monthly_HadCET_mean.txt, 1659 to date
- For each sample length (2, 5, 10, 20, 30, 40, 50, 100) the data was split into appropriate size samples starting from 1660.
- Where insufficient data was available at the end it was either ignored or if close enough to avoid major overlap, the sample was taken starting at an earlier date. (See table below)
- The slope was calculated for each sample.
- The standard deviation of sample slopes were calculated for each sample length.
- The standard deviation of all samples of each length was fitted to a polynomial against sample length. This produced a function estimating the expected standard deviation of slope for each sample length.
- The slope from each sample was then normalised (to give unity standard deviation), so that when plotted the temperature trend in sample would be shown on a scale relative to the standard deviation of that sample length.
Results
Typical Trends
Below is the summary table of the typical variation of trend seen for each period/sample length in the CET dataset. The second row is figure derived from the model as detailed below. The last row is the typical change we would expect in a period of this length. So, for example we would normally see around 0.45C variation from century to century and 0.83 variation from decade to decade.
| Period (yrs) | 2 | 5 | 10 | 20 | 30 | 40 | 50 | 100 | 1000 |
| Variation (C/yr) |
0.753 | 0.198 | 0.077 | 0.030 | 0.016 | 0.017 | 0.012 | 0.005 | – |
| Model (C/yr) |
0.643 | 0.201 | 0.083 | 0.035 | 0.021 | 0.014 | 0.011 | 0.004 | 0.002 |
| Model Period Change (C) |
1.29 | 1.00 | 0.83 | 0.69 | 0.62 | 0.57 | 0.54 | 0.45 | 0.24 |
Variation versus sample length
 |
 |
Above is the variation given by the standard deviation of trend shown against the sample length (shown as period length). The figure on the left is shown with a log vertical scale so that all sample lengths can be seen. That to the right has a linear vertical scale showing the sample length of interest so that they can be compared with the model.
These figures shows that for the period lengths analysed there is a close fit to a polynomial with a general downward slope whose value is:
Standard Deviation (C/yr) = 1.55 × period -1.27
This close fit shows that no period significantly deviates from the modelled power law relationship. As a significant deviation would be expected if any period had seen significant change from natural this is the first evidence against the hypothesis of abnormal behaviour.
Temperature Trend by year
In order to test the hypothesis of whether any abnormal trend exists, it was decided to first plot out the trends to see whether any abnormality was apparent. Below is a plot showing the normalised temperature trend for various lengths chunks by year.
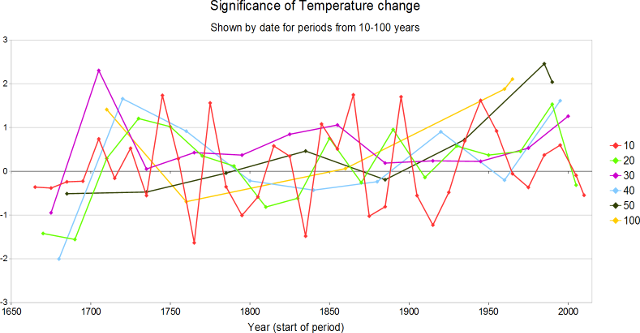 Note: Periods are plotted by average date
Note: Periods are plotted by average date
Analysis
- 10 year (red) – shows no significant trend with peaks of around ±1.5σ being common. There is no indication that the rate of warming within any ten year period is increasing since 1950. Recent trend is smaller than expected and the last period is negative.
- 20 year (green) – has similar sized peaks up to ±1.5σ. The highest trend occurs at the end of the series but this is not dissimilar to the earlier peak around 1720 nor other length periods
- 30 year (mauve) – similar to changes shown in 20 year period length except earlier peak is one of the largest approaching 2.5σ. However the recent trend is much smaller than would be expected.
- 40 year (light blue) – again similar to 20 year period length
- 50 year (black) – if taken out of context this plot would appear to show a significant trend, but when seen in context the scale of change is not abnormal. This plot shows the largest trend of 2.46σ. Thus we would expect 90% of the 5 data points from five different periods (although not independent) to be less than this. Therefore this deviation whilst larger than others cannot be said to be significant.
- 100year (yellow) – is again similar to other plots
Latest trend
| Measurement period (years) |
Trend relative to standard deviation |
End Year |
| 10 | -0.09 (-0.55) |
2000-2009 (2005-2014) |
| 20 | 1.53 (-0.32) |
1990-2009 (1995-2014) |
| 30 | 1.25 | 1985-2014 |
| 40 | 1975-2014 | |
| 50 | 2.46 (2.03) |
1960-2009 (1965-2014) |
| 100 | 1.88 (2.01) |
1910-2009 (1915-2914) |
From the visual analysis it was apparent that the most likely sample period to represent abnormal behaviour was the 50 year period ending in 2009.
Calculation of abnormality
The question that needed to be determined was not whether any one period in series of measurement was high, but whether given so many different periods were assessed, whether we would expect to get one so high. This is because there are so many different periods over which a trend could be assessed. So if we find one period that happens to be high, if to find this result we had considered several hundred ways of calculating such a trend, then clearly there is a much higher chance than if there is one and only one figure.
To use the example, if the 50 year trend is high, but not the 40,30,20,10 year trends, is this significant?
Whilst a figure of 2.5 standard deviations means that such a large deviation is atypical (~99%), if we looked at thousands of periods we would expect to get around 10 or so periods exceeding the 2.5 standard deviations. So we need to know the number of different samples considered.
In total there were around 80 different periods considered. However obviously a 40 year period overlapping with a 50 year period is likely to be very similar. So, if we find a high trend in one we would expect it in the other. These sample are not independent.
So, how many discrete sample do I have present? I chose to estimate this using the principle of selected samples that are likely to be orthogonal. One such group of orthogonal sample can be constructed by doubling the period of length of each sample. This suggests periods of 2.5, 5, 10,20, 40, 80 etc. With hindsight I would repeat the analysis with such periods, however as I only need an estimate of the number of independent samples, I chose to count only the periods of 10, 20, 50 & 100 years as the “population of sample”. I also discarded samples from the end.
In total this gave an estimate of 61 unique samples and therefore the question became within these 61 samples how unusual was the highest value seen (the 50 year normalised trend ending 2009).
This was calculated as follows:
If P is the probability of any one sample being at the standard deviation
Probability all 61 samples are lower = P61
This was calculated for both “warming” as in “being so high” and also “climate change” as in “being either so high or so low” with the following resutls
| 50 yr normalised trend ending |
Value (σ) |
Probabilty a sample lower |
Probabilty a sample closer to mean |
Probabilty all samples lower |
Probabilty all samples closer to mean |
| 2009 | 2.46 | 99.3% | 98.6% | 65.0% | 42.2% |
| 2014 | 2.04 | 97.9% | 95.8% | 27.8% |
Discussion
The hypothesis I wish to test was whether there is any trends within the Central England Temperature series is inconsistent with natural variation.
Within this analysis one of 50 years ending in 2009 was sufficiently high to be considered as possibly showing abnormality. However when assessed statistically I found that the chance of this being abnormal climate variation was only 42.2%. Therefore the data does reject the null hypothesis which is that the dataset is due to natural variation.
However, if instead of “climate variation”, we only consider “warming”, there is a 65% probability that the single 50 year period ending in 2009 should be lower in a normal distribution. But, if the hypothesis of “current warming” is to be supported, it must not only be true in 2009 but also true in all later periods including the latest in 2014. Therefore the probability that the current 50 year trend (to 2014) is abnormal is only 27.8% which means that current warming is not supported from the CET dataset.
Given the correlation between CET and global temperatures, I can therefore conclude that it is unlikely that either current “global warming” or “climate change” is abnormal or departs significantly from what we expect of normal natural climatic variation.

Obviously a much saner approach than the data cherry picking that has been used by advocates of the “exeptional climate change/global warming” hypothesis!
Obviously, the science is not “settled”! M Newhouse
Interesting and logical seeming approach. I do not have the math to agree or disagree with your result but it was relatively easy to follow your description of how you got there. I am a little surprised I haven’t seen this done before. I think your comparison of the CET with global averages makes the case for validity of using CET as a proxy. Where did you get the global average from? The charts show the importance picking your start dates.
Paul Stevens
Yes it is amazing that people go to the wilds of yamal to find bits of wood which they have no idea how or if it represents global temperature, and then they “hide the decline” in tree ring proxies as they don’t fit modern temperatures and pretend that even though they don’t fit modern temperatures they somehow tell us about the past …
… when all along there was a perfectly good proxy which shows that we are not living through a period of unusual climate change.
Why on earth would any real scientist ignore this proxy?
The global average is the HADCRUT4.
Why on earth would any real scientist ignore this proxy?
============
climate science is the search for positive examples, as per all pseudo science. The CET provides a negative example, thus not interesting, except in the world of real science.
Pseudo science believes something to be true based on the number of positive examples outweighing the negative examples. In other words, science by vote. True science believes something is true only if there is no example showing it to be false.
CET shows current warming is not abnormal, thus disproving AGW. In any other branch of science this would constitute proof that AGW is false. However, in climate science, all that is required is two examples that current worming is not normal, and this would outweigh the CET example.
Because of this, whether AGW is true of false then becomes a matter of funding. The side that does the most studies proves their position is true. The side that does the least studies proves their side is false. Not because of true or false, rather simply as a result of the number of studies.
In other words, climate science has been reduced to stuffing ballot boxes.
I saw a really good example of this on this appalling thing:
http://www.bloomberg.com/graphics/2015-whats-warming-the-world/?utm_content=bufferc2b8b&utm_medium=social&utm_source=twitter.com&utm_campaign=buffer
When you know that CET shows as much warming in the past without CO2, rise, then quite clearly, unless the variation is as large without CO2 as it was in the past, then your model is quite clearly and unequivocally wrong.
So, rather like going from a bumpy road to a flat road – and just by how bumpy it is you’ll know if you are on the same road, so if the present isn’t as “bumpy” as the past, then they’ve clearly and unequivocally got it wrong.
But instead, the actual “bump” they had was CO2 – massively scaled up by fictional “feedbacks” – so it is quite obvious that they are just mistaking normal natural variation for the effect of CO2.
Scottish sceptic
I recently reconstructed CET to 1538
Clearly the period 1690 to 1740 was the most unusual spike in temperatures in the record
http://judithcurry.com/2015/02/19/the-intermittent-little-ice-age/
CET is well known in many scientific circles to be a reasonable proxy for global temperatures or even more closely NH temperatures. Hubert lamb saw the connection some 50 Years ago and in the modern era the Met office, the Dutch met office and mike Hulme have all seen the connection.
Better than tree rings as CET relies on instruments and a host of observed data to produce its data.
Tonyb
Tonyb thanks for that. I had hoped it was done and dusted once and for ever, but with so much more data it would be interesting to see what I get. A quick look suggests that it won’t be much different, but with nearly 500 years I would clearly get more robust noise figures for the 50,100 and perhaps I might even extend it to 200 years?
I often commented on the 1690-1740 rise, so I was just wondering why the 1690-1740 spike didn’t come up strongly on my own analysis. But thinking about it I was doing it 1660-1709 and 1710 – 1760 which just doesn’t pick it up so strongly. (No one can claim I was cherry picking to highlight that!)
Now I think about it, I might be able to add another group of tends starting at half the period length. That would be equivalent to a 1/4 cycle (if the periods were square waves) which would be like the sin+cos of fourier analysis.
The other approach is to do a continuous running average, take the variance of that, and then scale so it has the same weight as now.
Tony, I’ve looked at how you reconstructed CET and thinking about it, the variability would clearly change if I used a very different reconstruction for temperature. But I’ll think about it.
OT :- ice ages!
Hi Scottish Sceptic,
Just reading your post about ice age causation and thought I would share my ideas.
My theory on ice ages is simple, they are caused by acceleration of thermohaline circulation with a positive feedback coming from increased brine formation due to increased sea ice formation because of the triangular shape of the north atlantic coast. Deglaciation is triggered by insolation changes once a significant period of dust accumulation occurs at the bottom of the cycle resulting in large meltwater pulse and disruption THC. All working engine and radiator theory (zonal/meridonal flow patterns) and fits with thermodynamic/Gibbs free energy principles ect. Ie the world is cycling between two energy minimal states (high kinetic/low thermal and low kinetic/high thermal)
cheers
Rob
I’m a regular contributor at the sceptic italian blog
http://www.climatemonitor.it and found your analysis of the CET interesting. I
tried to reproduce it following your post and had no problem to obtain a
graph very similar to your first figure (I don’t use period 2 and my period
5 is actually incomplete).
I have some problem with your figure quoted “Significance of Temperature
change”: I can produce a plot of almost the same shape of yours but, while
your maxima of (slope/sigma) are some 2.5 sigma, my values are ~4 sigma and
for period 50, ~5.8 sigma. Of course, any comment given for 2.5 sigma cannot
be valid for 4-6 sigma, so my analysis stops here.
Your data are not available for a comparison, so I’ve prepared a .tar with
my plots and data, in the hope you can look at it and comment. The link is
http://www.zafzaf.it/clima/cet.tar (1.5 MB). When uncompressed, the tar
ball creates the directory cet/, organized like a web page.
Click on cethome.html to make available my data.
Regards
Franco Zavatti
Thanks. I’ve just realised that as I’ve been doing a lot more work on later versions, I’m not sure I’ve got that graph in the current version (and openoffice is refusing to show graphs).
The figures are the average slope (using openoffice slope()) function over the period dividing by the standard deviation of the trend. (it was straight, I’m now using population).
So, if there’s S1 = slope(1660:1710), S2=slope(1710:1760), … Sn, and Sd = STDEV(s1,s2,.. sn) then in that article the figures should be S1/Sd, S2/Sd, etc.
However, since doing the original article, after looking at a lot of graphs derived from noise, I’ve realised that because this graph is inherently periodic, it makes more sense to use a scale related to “peak”. So rather than just divide by the Standard deviation I’m now using Sd.2^.5.
This then means that a standard deviation of 2 is uncommon and one of 3 is exceptional which much better fits in with how these figures are usually interpreted (before I was regularly getting well in excess of 3).
I wonder whether in preparing a later article I may have changed the above graph in that article which effectively changed it in this
OK, I found I had kept an early version.
Checking the spreadsheet. It’s just
Slope(period) /calibration
Calibration = (1.55(T^-1.27))
T=number of years in slope
The calibration is a best fit curve to the function “STDEV” on calc. After thinking about it, this is the wrong standard deviation, but it gives a higher figure than population standard deviation so doesn’t change the conclusion (and I like to know I’ve erred on side of caution).
Thanks. Now (almost) anything is clear and I’ll check my data also against a noise function. And I agree with you about to err on side of caution.
Franco
Pingback: Scientists: Join Prof Kelly or get booed off the lectern. | Scottish Sceptic
Pingback: A sceptic’s view of climate | Scottish Sceptic
Pingback: What evidence would convince me re Global warming | Scottish Sceptic
Pingback: Most useful links when explaining climate science to alarmists | Scottish Sceptic
Pingback: Understanding the Global Temperature II | Scottish Sceptic